In this case study we implement and test methods for probabilistic forecast reconciliation based on the recent papers by Panagiotelis et al. (2022) and Zambon, Azzimonti, and Corani (2022).
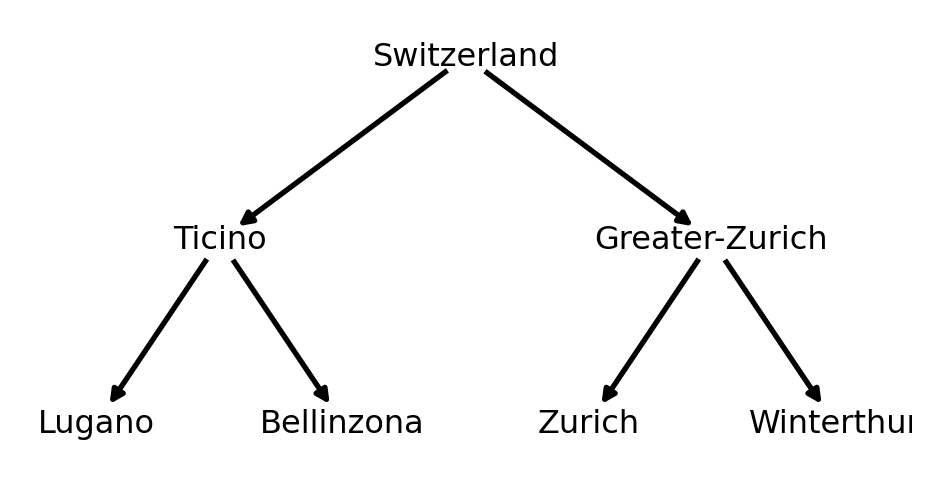
Forecast reconciliation is often found in hierarchical time series analysis scenarios, i.e., where time series can be (dis-)aggregated linearly by various attributes in a hierarchical way. For instance, consider a scenario in retail forecasting where we are interested in predicting the number of sold books per day. Forecasts are often required for all levels of a hierarchy, i.e., for the time series on the very bottom (e.g., cities), the inner nodes of a hierarchy (e.g., regions, counties) and the root node of the hierarchy (e.g., country) and it is natural to want the forecasts to add up in the same way as the data. For example, forecasts of sales per city should add up to forecasts of sales per canton, etc. In this case the hierarchy is induced by the granularity of the location as exemplified by the tree below:
Propabilistic forecast reconciliation aims at generating coherent probabilistic forecasts over all levels of the hierarchy.
Before we implement the two methods introduced in Panagiotelis et al. (2022) and Zambon, Azzimonti, and Corani (2022), we briefly introduce probabilistic reconciliation. We then implement and test the two methods where we use GPJax to produce forecasts with Gaussian processes. I bundled the code for this case study as a Python package called reconcile which can be found here.
import distraximport gpjax as gpximport jaxfrom jax import numpy as jnpfrom jax import randomimport numpy as npimport optaximport pandas as pdimport pathlibfrom reconcile.forecast import Forecasterfrom reconcile.grouping import Groupingfrom reconcile.probabilistic_reconciliation import ProbabilisticReconciliationimport matplotlib.pyplot as pltimport seaborn as snsimport palettesfrom jax.config import configconfig.update("jax_enable_x64", True)
<frozen importlib._bootstrap>:228: RuntimeWarning: scipy._lib.messagestream.MessageStream size changed, may indicate binary incompatibility. Expected 56 from C header, got 64 from PyObject
Probabilistic reconciliation
Denote with \(\mathbf{b}^t \in \mathbb{R}^P\) a vector of observations of “bottom-level” time series at time \(t\) and with \(y^t_{n}\) an observation of node \(n\) at time \(t\). For instance, in the example above \(\mathbf{b}^t = \{y^t_{\text{Lugano}}, y^t_{\text{Bellinzona}}, y^t_{\text{Zurich}}, y^t_{\text{Winterthur}} \}\). We can aggregate the bottom level observations such that the parents of nodes are sums of their children, via an summing matrix \(\mathbf{S} \in \{0, 1\}^{Q \times P}\)
\[
\mathbf{y}^t = \mathbf{Sb}
\]
where \(\mathbf{S}\) defines the hierarchical structure of the time series. Again, as an example, for the hierarchy above
where \(\mathbf{A}\) is called aggregation matrix, \(\mathbf{I}\) is a diagonal matrix, and the vector \(\mathbf{y}^t =\{y^t_{\text{Switzerland}}, y^t_{\text{Ticino}}, y^t_{\text{Greater-Zurich}}, y^t_{\text{Lugano}},y^t_{\text{Bellinzona}}, y^t_{\text{Zurich}}, y^t_{\text{Winterthur}}\}\) contains all the time series over the hierarchy. When we generate forecasts \(\hat{\mathbf{y}}\) for all of these timeseries, they might not cohere to the linear constraints induced by the hierarchy.
In a probabilistic (e.g., Bayesian) framework forecasts are available in the form of probability distributions. Following Zambon, Azzimonti, and Corani (2022), we denote \(\hat{\nu} \in \mathbb{P}(\mathbb{R}^Q)\) the forecast distribution of \(\hat{\mathbf{y}}\) and call it coherent (\(\tilde{\nu}\)) if \(\text{supp}(\hat{\nu})\) is in a linear subspace \(\mathcal{S}\) of dimension \(P\) of \(\mathbb{R}^Q\).
To find a coherent forecast distribution \(\tilde{\nu}\), Panagiotelis et al. (2022) propose to fit a map \(\psi: \mathbb{R}^Q \rightarrow \mathcal{S}\), such that \(\tilde{\nu} = \psi_{\sharp}\hat{\nu}\). Panagiotelis et al. (2022) use a simple linear transformation \(\psi(\mathbf{y}) = \mathbf{S}(\mathbf{d} + \mathbf{W}\mathbf{y})\) and fit it using an approximate energy score as objective.
Zambon, Azzimonti, and Corani (2022) propose sampling from the reconciled base forecast density \(\tilde{\pi}(\mathbf{b})\) of \(\mathbf{b}\) via \(\tilde{\pi}(\mathbf{b}) \propto \pi_U(\mathbf{A}\mathbf{b}) \pi_B(\mathbf{b})\) where \(\mathbf{A}\) is the aggregation matrix, and \(\pi_U\) and \(\pi_B\) are the predictive densities of the upper level time series, i.e., the ones corresponding to the inner nodes and root, and bottom level time series.
For further details, please refer to the original publications.
Data
We will test the two methods on a finance data set, specifically stock index data of some constituents of the SP500 which we take from datahub and Kaggle.
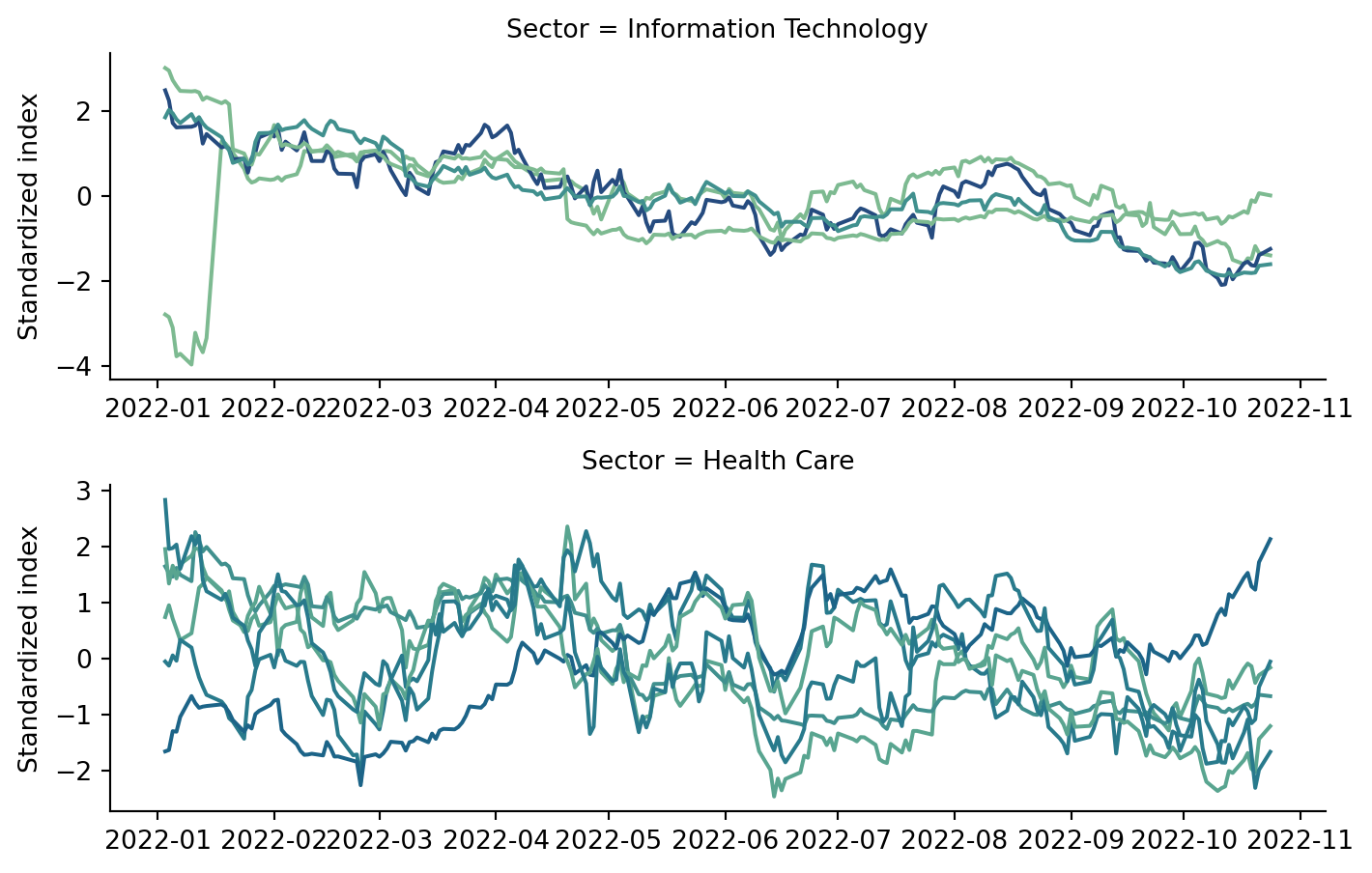
Of the SP500, we somewhat arbitrarily picked some consituents from the health care and information technology industries and selected all entries from 2022 on. In that case the hierarchy consists of two levels, where “Health Care” and “Information Technology” are the parents of the different companies (which are leaves).
Before we try start forecasting these, we postprocess the data, e.g., by transforming the dates into numeric values and then extract them from the data frame as arrays.
Using reconcile we can define a hierarchy (or more generally a grouping) using the Grouping class. To do so, we first create a “:”-separated string for every bottom level time series that specifies the path of the time series to the root of the hierarchy.
Since in our example, the hierarchy is very flat (only one inner level), the strings are only separated by one colon. For instance “Boston Scientific” is in the health care sector, hence we create an entry “Health Care:Boston Scientific”. We then create a grouping using the list of strings.
groups = pd.DataFrame({"hierarchy": hierarchy})grouping = Grouping(groups)
Forecasts
Before we can probabilistically reconcile forecasts, we first need to generate probabilistic forecasts (yupp), or rather predictive distributions. We use GPJax’s Gaussian process implementations for this. Specifically, we fit a Gaussian process to every time series separately and then, in a post-processing step, reconcile those forecasts.
GPs are arguably not the best model here, but for the sake of demonstrating the two reconciliation methods it is fine, since we don’t aim to make perfectly accurate predictions here.
We first get all the time series, i.e, bottom and upper level time series, from the Grouping object.
We then define a forecasting class. The class needs to inherit from Forecaster which is implemented in the Python package we developed for this case study. The class needs to provide a fit method that fits all of the time series, a posterior_predictive method which returns a posterior predictive distribution of all time series as distrax object, and a method predictive_posterior_probability that computes the probabilty of observing some event under the posterior predictive.
class GPForecaster(Forecaster):"""Example implementation of a forecaster"""def__init__(self):self._models = []self._xs =Noneself._ys =None@propertydef data(self):"""Returns the data"""returnself._ys, self._xsdef fit(self, rng_key, ys, xs):"""Fit a model to each of the time series"""self._xs = xsself._ys = ys p = xs.shape[1]self._models = [None] * pfor i in np.arange(p): x, y = xs[:, [i], :], ys[:, [i], :]# fit a model for each time series learned_params, D =self._fit_one(rng_key, x, y)# save the learned parameters and the original dataself._models[i] = learned_params, Ddef _fit_one(self, rng_key, x, y):# here we use GPs to model the time series D = gpx.Dataset(X=x.reshape(-1, 1), y=y.reshape(-1, 1)) posterior, likelihood =self._model(rng_key, D.n) parameter_state = gpx.initialise(posterior, key=rng_key) mll = jax.jit(posterior.marginal_log_likelihood(D, negative=True)) optimiser = optax.adam(learning_rate=5e-2) inference_state = gpx.fit(mll, parameter_state, optimiser, n_iters=2000, verbose=False) learned_params, _ = inference_state.unpack()return learned_params, D@staticmethoddef _model(rng_key, n): D = gpx.Dataset(X=x[0, 0].reshape(-1, 1), y=b[0, 0].reshape(-1, 1)) kernel = gpx.RBF() + gpx.Matern32() prior = gpx.Prior(mean_function=gpx.Constant(), kernel=kernel) likelihood = gpx.Gaussian(num_datapoints=D.n) posterior = prior * likelihoodreturn posterior, likelihooddef posterior_predictive(self, rng_key, xs_test):"""Compute the joint posterior predictive distribution of all timeseries at xs_test""" q = xs_test.shape[1] means = [None] * q covs = [None] * qfor i in np.arange(q): x_test = xs_test[:, [i], :].reshape(-1, 1) learned_params, D =self._models[i] posterior, likelihood =self._model(rng_key, D.n) latent_distribution = posterior(learned_params, D)(x_test) predictive_dist = likelihood(learned_params, latent_distribution) means[i] = predictive_dist.mean() cov = jnp.linalg.cholesky(predictive_dist.covariance_matrix) covs[i] = cov.reshape((1, *cov.shape))# here we stack the means and covariance functions of all# GP models we used means = jnp.vstack(means) covs = jnp.vstack(covs)# here we use a single distrax distribution to model the predictive# posterior of _all_ models posterior_predictive = distrax.MultivariateNormalTri(means, covs)return posterior_predictivedef predictive_posterior_probability(self, rng_key, ys_test, xs_test ):"""Compute the log predictive posterior probability of an observation""" preds =self.posterior_predictive(rng_key, xs_test) lp = preds.log_prob(ys_test)return lp
The time series have a total length of 204 of which we take the first 200 for training.
/Users/simon/miniconda3/envs/etudes/lib/python3.9/site-packages/gpjax/parameters.py:180: UserWarning: Parameter constant has no transform. Defaulting to identity transfom.
warnings.warn(
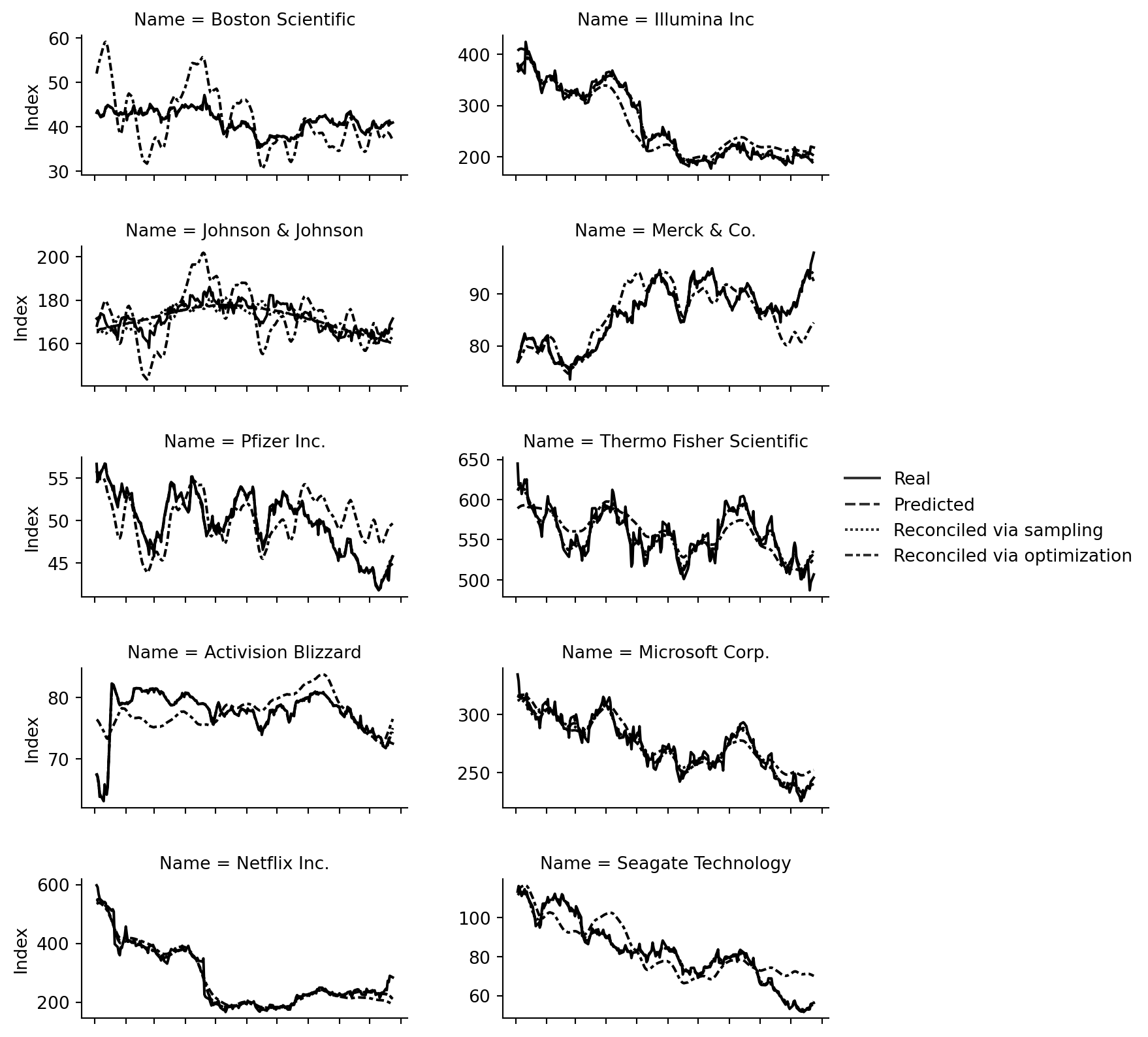
As baseline to the two reconciliation methods, we also sample from the posterior predictive of the base forecasts.
Let’s visualize the results. We first aggregate all forecasts in a data frame and then plot the original data, the base forecasts and the two recconciled forecasts.
The results look decent for some of the time series and even worse than the base forecasts for others. Given that the time series don’t present clear trends or saisonalities, the task was arguably a very difficult one though.
Conclusion
This case study implemented and tested two methods based on recent papers on probabilstic forecast reconciliation. We evaluated the methods (superficially) on stock-index time series data of the SP500 with mixed results. Stock-index data is notoriously hard to forecast due to their (apparent) stationarity, and the evaluation was consequently not very meaningful, but rather intended to understand probabilistic reconciliation methods better.
The methods demonstrated above are implemented in a Python package called reconcile which can be found on PyPI and GitHub.
Panagiotelis, Anastasios, Puwasala Gamakumara, George Athanasopoulos, and Rob J Hyndman. 2022. “Probabilistic Forecast Reconciliation: Properties, Evaluation and Score Optimisation.”European Journal of Operational Research.
Zambon, Lorenzo, Dario Azzimonti, and Giorgio Corani. 2022. “Probabilistic Reconciliation of Forecasts via Importance Sampling.”arXiv Preprint arXiv:2210.02286.