Diffusion models II: DDPMs, NCSNs and score-based generative modelling using SDEs
Author
Simon Dirmeier
Published
January, 2023
The following case study introduces recent developments in generative modelling using diffusion models. We will first introduce two landmark papers on diffusion models, “Denoising Diffusion Probabilistic Models” (Ho, Jain, and Abbeel 2020) and “Generative Modeling by Estimating Gradients of the Data Distribution” (Song and Ermon 2019), and then examine a general framework introduced in Song et al. (2021) that unifies both. This case study is the second in a series on diffusion models: please find the first one here.
We’ll reimplement all three vanilla models using Jax, Haiku and Optax.
Code
import warningswarnings.filterwarnings("ignore")from dataclasses import dataclassimport distraximport haiku as hkimport numpy as npimport jaximport optaximport pandas as pdfrom jax import lax, nn, jit, gradfrom jax import numpy as jnpfrom jax import randomfrom jax import scipy as jspfrom scipy import integrateimport arviz as azimport matplotlib.pyplot as pltimport palettesimport seaborn as snssns.set(rc={"figure.figsize": (6, 3)})sns.set_style("ticks", {"font.family": "serif", "font.serif": "Merriweather"})palettes.set_theme()
where every transition \(p_\theta(\mathbf{y}_{t-1} \mid \mathbf{y}_{t})\) is parameterized by the same neural network \(\theta\) and trained by optimizing a lower bound on the marginal log-likelihood:
In comparison to other latent variables models, DPMs use an approximate posterior \(q\left(\mathbf{y}_{1:T} \mid \mathbf{y}_0 \right) = q(\mathbf{y}_{1} \mid \mathbf{y}_0) \prod_{t=2}^T q(\mathbf{y}_{t} \mid \mathbf{y}_{t - 1})\) that is fixed to a Markov chain and which repeatedly adds noise to the initial data set, while the joint distribution \(p_\theta \left( \mathbf{y}_0, \mathbf{y}_{1:T} \right)\) is learned. As discussed in the previous case study, the ELBO above can be reformulated as
which can be computed in closed form. The insight from Ho, Jain, and Abbeel (2020) is that the objective above can be simplified (and numerically stabilized) by setting the covariance matrix of the reverse process \(p_\theta \left(\mathbf{y}_{t-1} \mid \mathbf{y}_{t} \right) = \mathcal{N}\left(\boldsymbol \mu_\theta \left(\mathbf{y}_{t}, t\right), \boldsymbol \Sigma(\mathbf{y}_{t}, t)\right)\) to a constant \(\boldsymbol \Sigma \left(\mathbf{y}_{t}, t \right) = \sigma_t^2\mathbf{I}\). The divergence between the forward process posterior and the reverse process can then be written as
So, we can parameterize \(\boldsymbol \mu_\theta\) using a model that predicts the forward process posterior mean \(\tilde{\boldsymbol \mu}\). We can further develop this formulation by applying the usual Gaussian reparameterization trick and arrive at an objective that is significantly more stable to optimize than the initial ELBO, but for the sake of this case study we will not derive the math here and refer the read to the original publication.
In practice, we just sample a time point \(t\) and then don’t optimze the entire objective but only
where we denote - with a slight abuse of notation - \(t\) as both a time point and the distribution of time points over which the expectation is taken.
To generate new data, we sample first from the prior \(p_T\) and then iteratively denoise the sample until we reach \(p_\theta(\mathbf{y}_0 \mid \mathbf{y}_1)\).
NCSNs
Similarly to DDPMs, noise-conditional score networks (NCSNs, Song and Ermon (2019)) are generative models that make use of noising the data and then trying to train a network that can denoise this process. Unlike DDPMs, NCSNs are motivated through score-matching (Hyvärinen and Dayan 2005) where we are interested in finding a parameterized function \(\mathbf{s}_\theta\) that approximates the score of a data distribution \(q(\mathbf{y})\). Score matching optimizes the following objective
In denoising score matching (Vincent 2011), we denoise a data sample with a fixed noise distribution \(q_\sigma \left(\tilde{\mathbf{y}} \mid \mathbf{y} \right) = \mathcal{N}\left(\mathbf{y}, \sigma^2 \mathbf{I} \right)\) to estimate the score of \(q_\sigma \left(\tilde{\mathbf{y}} \right) = \int q_\sigma \left(\tilde{\mathbf{y}} \mid \mathbf{y} \right) p(\mathbf{y})\). Vincent (2011) show that the objective proved equivalent to:
In practice, generative modelling using this objective faces two difficulties. One is that if \(\mathbf{y}\) is embedded in a low-dimensional manifold, the gradient taken in the ambient space is undefined. The score estimator is not consistent if the data are residing in a low-dimensional space. Secondly, for regions where there is low data density the score estimator is not accurate.
Song and Ermon (2019) work around both issues by perturbing the data set with multiple levels of noise \(\{ \sigma_i \}_{i=1}^L\) and training a score network that is conditional on the noise levels \(\mathbf{s}\left(\tilde{\mathbf{y}}, \sigma_i \right)\). The authors propose the following objective to train a model of the data:
where \(\lambda(\sigma_i)\) is a weighting function that is chosen to be proportional to \(\lambda(\sigma_i) \propto 1 / \mathbb{E}\left[ \|\nabla_{\mathbf{y}} q_\sigma \left(\tilde{\mathbf{y}} \mid \mathbf{y} \|^2_2 \right) \right]\).
To draw samples from the trained model, Song and Ermon (2019) propose using annealed Langevin dynamics where we only need access to the score function of a density to propose new samples (which we just learned).
Score-based SDEs
Before we introduce score-based SDEs, let’s have a look at the DDPM and NCSN objectives again.
Similarities
Let’s first recall that in the DDPM framework we parameterize a model using a neural network \(\boldsymbol \mu_\theta \left(\mathbf{y}_t, t \right)\) to predict the forward process posterior mean \(\tilde{\boldsymbol \mu}\left(\mathbf{y}_t, \mathbf{y}_0 \right) =\frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{y}_t + \frac{\sqrt{\bar{\alpha}_{t-1} } \beta_t}{1 - \bar{\alpha}_{t}} \mathbf{y}_0\). We recognize that since we actually have access to \(\mathbf{y}_t\), we can alternatively make \(\boldsymbol \mu_\theta \left(\mathbf{y}_t, t \right)\) predict \(\mathbf{y}_0\).
Now, if we recall that \(q(\mathbf{y}_t \mid \mathbf{y}_0) = \mathcal{N}\left(\sqrt{\bar{\alpha_t}} \mathbf{y}_0, \left(1 - \bar{\alpha}_t \right) \mathbf{I} \right)\) and compute the partial derivate of its logarithm w.r.t \(\mathbf{y}_t\)
So we can alternatively use a model \(\mathbf{s}_\theta (\mathbf{y}_t, t)\) to predict the score \(\nabla_{\mathbf{y}_t} \log q(\mathbf{y}_t)\) and define the objective:
where \(\lambda\) is again a weighting function. This makes the relationship between DDPMs and NCSNs obvious, since the denoising score-matching objective is also used in NCSNs.
A common framework
Song et al. (2021) explain that the diffusion processes of DDPMs and NCSNs can be described as an Ito SDE
where \(\mathbf{f}\) is called drift coefficient, \(\mathbf{g}\) is called diffusion coefficient and \(\mathbf{w}\) is a Wiener process. The process starts at a data sample \(\mathbf{y}(0) \sim q(\mathbf{y}(0))\) and continuously corrupts it. The DDPM and NCSC are two special discrete-time cases of this process. In case of the DDPM objective, the corresponding SDE is
where \(q_{st}(\mathbf{y}(t) \mid \mathbf{y}(s))\) is a transition kernel that generates \(\mathbf{y}(t)\) from \(\mathbf{y}_s\).
After having trained this objective, we are interested in using the reverse process again to geerate samples. Remarkably, Anderson (1982) state that the reverse of diffusion process is also a diffusion process that runs backward in time. Specifically:
where \(\bar{\mathbf{w}}\) is a Wiener process that runs reverse in time and \(t\) is a negative timestep. So, in order to train a score-based SDE need to define the forward process. Two options of which are the DDPM and the NCSN, but in general we are free to define any SDE that is a Ito process.
A particularly useful insight fom the paper is that for every diffusion process there exists a corresponding deterministic diffusion process that has the same marginal densitities \(q_t\) as the SDE. This deterministic is an ODE
which can be solved using any publically available ODE solver.
Use cases
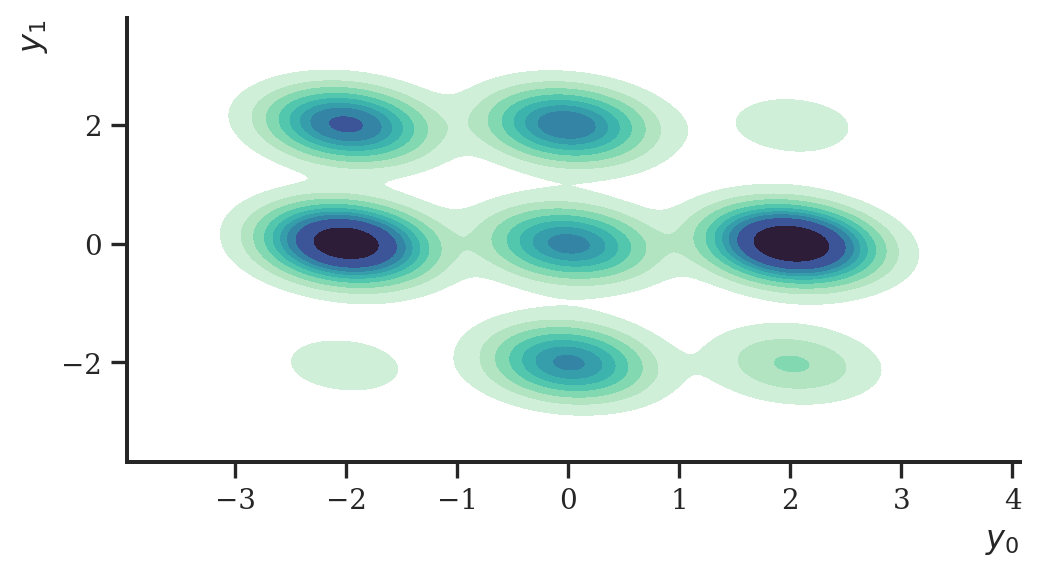
Let’s implement these three models and compare them. We use the nice Gaussians data set again as in the last case study on diffusion models. The nine Gaussians data set is shown below.
We start by implementing a model, i.e., the neural network that estimates the score, noise, etc. We can use the same model for NCSNs, DDPMs, and score-based SDEs. We can also use the same embedding function for the time points and noise levels used in the NCSNs and DDPMs. As a model, we use a simple MLP with gelu activations and a normalisation layer at the end.
from dataclasses import dataclassdef get_embedding(inputs, embedding_dim, max_positions=10000):assertlen(inputs.shape) ==1 half_dim = embedding_dim //2 emb = jnp.log(max_positions) / (half_dim -1) emb = jnp.exp(jnp.arange(half_dim, dtype=jnp.float32) *-emb) emb = inputs[:, None] * emb[None, :] emb = jnp.concatenate([jnp.sin(emb), jnp.cos(emb)], axis=1)return emb@dataclassclass ScoreModel(hk.Module): output_dim =2 hidden_dims = [256, 256] embedding_dim =256def__call__(self, z, t, is_training): dropout_rate =0.1if is_training else0.0 t_embedding = jax.nn.gelu( hk.Linear(self.embedding_dim)(get_embedding(t, self.embedding_dim)) ) h = hk.Linear(self.embedding_dim)(z) h += t_embeddingfor dim inself.hidden_dims: h = hk.Linear(dim)(h) h = jax.nn.gelu(h) h = hk.LayerNorm(axis=-1, create_scale=True, create_offset=True)(h) h = hk.dropout(hk.next_rng_key(), dropout_rate, h) h = hk.Linear(self.output_dim)(h)return h
NCSN
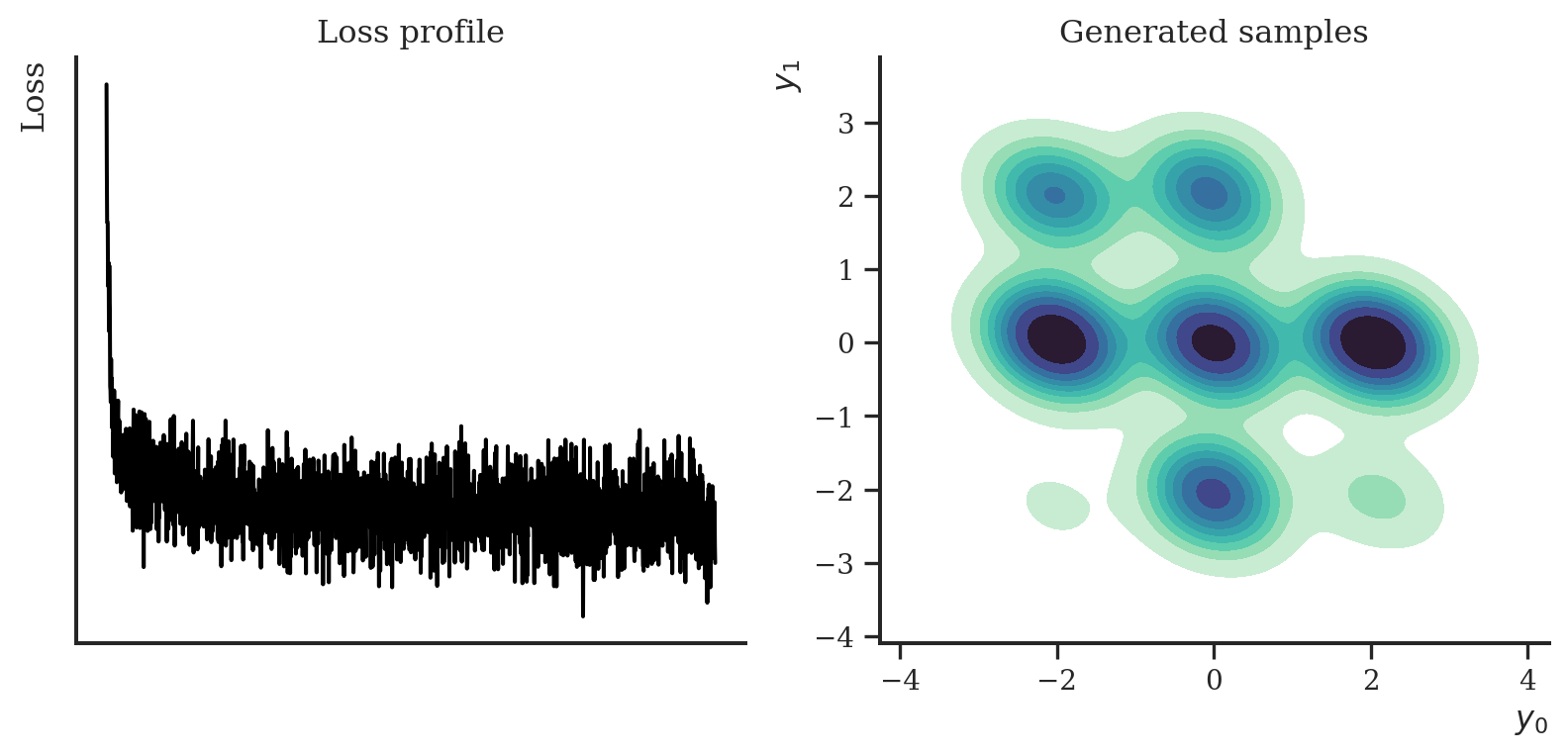
We start with the NCSN. The implementation is fairly straight-forward and exactly as described above. It consists of a loss function, and a function to sample new data using annealed Langevin dynamics. We provide a score model and a noise schedule to the constructor and that’s all that is needed.
Using Haiku, we need to transform the intialisation of a NCSN object. As a noise schedule, we use a geometric sequence from 1 to 0.01, similarly as to the paper.
Having trained the model, let’s visualize the trace of the loss and draw some samples. The samples should look similarly to the original data set, the 9 Gaussians.
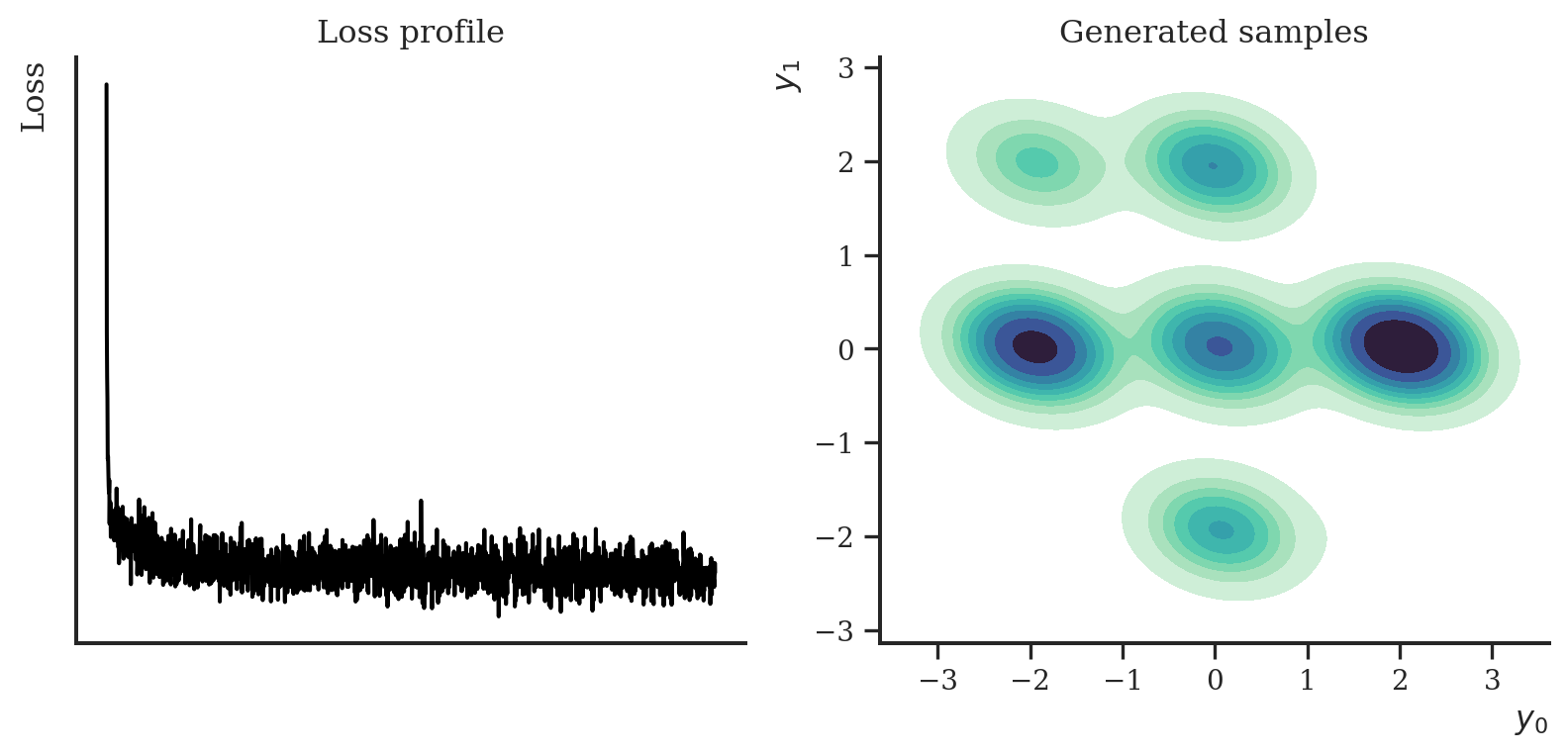
The DDPM implementation looks almost identical. Instead of a noise schedule, we supply a vector of \(\beta\)s. In comparison to the NCSN, we don’t need to use Langevin dynamics to sample new data, but can run the Markov chain in reverse. Here, we choose to use the parameterization from the paper which predicts the noise \(\boldsymbol \epsilon\) that is used to generate a latent variable \(\mathbf{y}_t\), but it is equivalent to predicing the mean of the forward process posterior.
class DDPM(hk.Module):def__init__(self, score_model, betas):super().__init__()self.score_model = score_modelself.n_diffusions =len(betas)self.betas = betasself.alphas =1.0-self.betasself.alphas_bar = jnp.cumprod(self.alphas)self.sqrt_alphas_bar = jnp.sqrt(self.alphas_bar)self.sqrt_1m_alphas_bar =jnp.sqrt(1.0-self.alphas_bar)def__call__(self, method="loss", **kwargs):returngetattr(self, method)(**kwargs)def loss(self, y, is_training=True): t = random.choice( key=hk.next_rng_key(), a=jnp.arange(0, self.n_diffusions), shape=(y.shape[0],), ).reshape(-1, 1) noise = random.normal(hk.next_rng_key(), y.shape) perturbed_y = (self.sqrt_alphas_bar[t] * y +self.sqrt_1m_alphas_bar[t] * noise ) eps =self.score_model( perturbed_y, t.reshape(-1), is_training, ) loss = jnp.sum(jnp.square(noise - eps), axis=-1)return lossdef sample(self, sample_shape=(1,)):def _fn(i, x): t =self.n_diffusions - i z = random.normal(hk.next_rng_key(), x.shape) sc =self.score_model( x, jnp.full(x.shape[0], t),False, ) xn = (1-self.alphas[t]) /self.sqrt_1m_alphas_bar[t] * sc xn = x - xn xn = xn / jnp.sqrt(self.alphas[t]) x = xn +self.betas[t] * zreturn x z_T = random.normal(hk.next_rng_key(), sample_shape + (2,)) z0 = hk.fori_loop(0, self.n_diffusions, _fn, z_T)return z0
Just as in the original publication, we define a \(\beta\)-schedule a linear sequence.
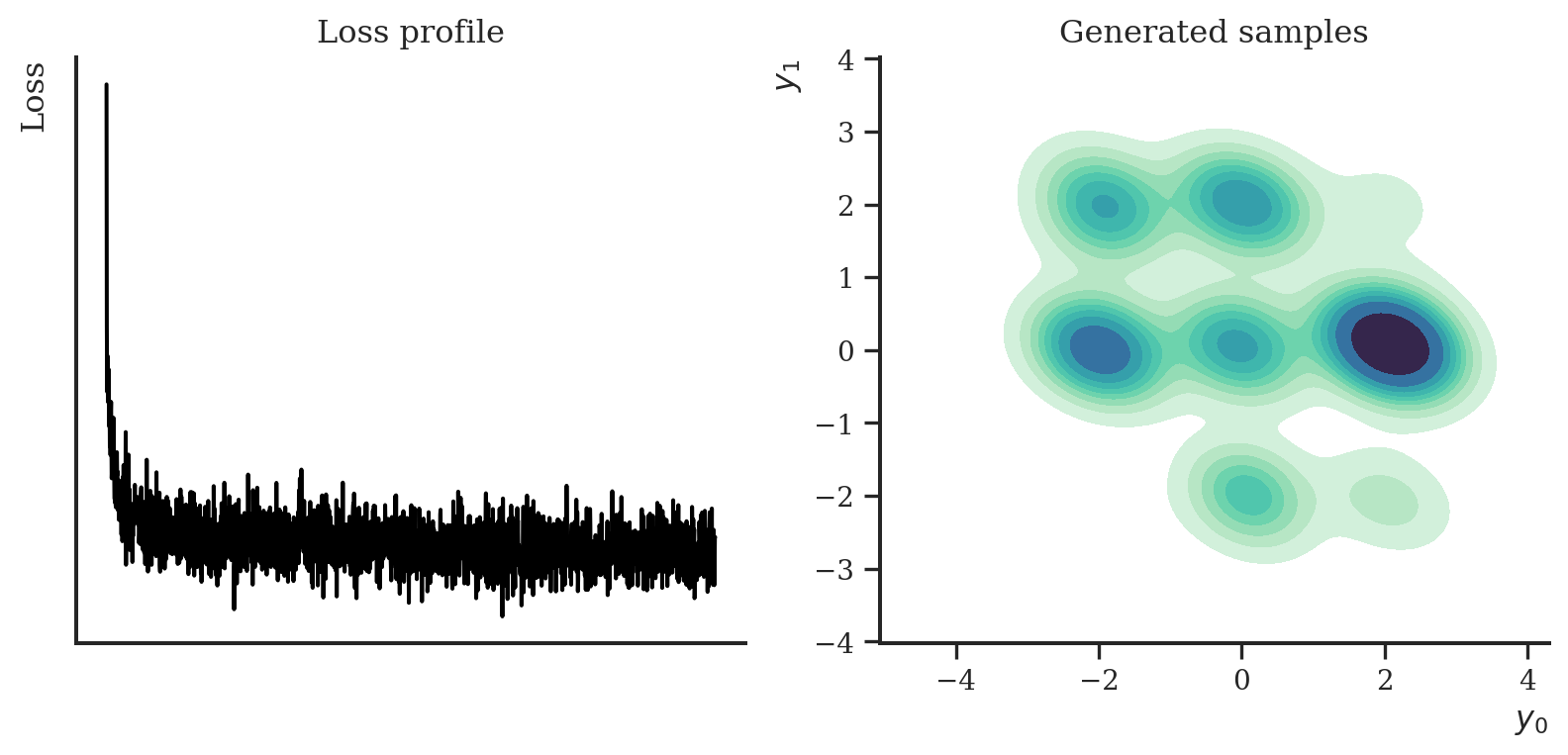
Finally, we implement a continuous-time diffusion model using stochastic differential equations. Again, the base implementation is fairly similar to the models before. The only thing we have to adapt in comparison to the NCSN is that we now provide a function that computes the mean and standard deviation for the transition kernel \(p_{st}(\mathbf{y}(t) \mid \mathbf{y}(s))\) and one function that computes the drift and diffusion coefficients of the forward and reverse SDEs (which are identical in both directions).
Here, for some variate we will choose the sub variance-preserving SDE from the original publication:
This case study implemented three recent developments in generative diffusions. We first implemented the NCSN and DDPM objectives, and then the framework by Song et al. (2021) which turned out to be a continuous time generalisation of both models. In terms of sample quality, for the nine Gaussians data set the results are somewhat similar.
Anderson, Brian DO. 1982. “Reverse-Time Diffusion Equation Models.”Stochastic Processes and Their Applications 12 (3): 313–26.
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. 2020. “Denoising Diffusion Probabilistic Models.”Advances in Neural Information Processing Systems 33: 6840–51.
Hyvärinen, Aapo, and Peter Dayan. 2005. “Estimation of Non-Normalized Statistical Models by Score Matching.”Journal of Machine Learning Research 6 (4).
Sohl-Dickstein, Jascha, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. “Deep Unsupervised Learning Using Nonequilibrium Thermodynamics.” In International Conference on Machine Learning, 2256–65. PMLR.
Song, Yang, and Stefano Ermon. 2019. “Generative Modeling by Estimating Gradients of the Data Distribution.”Advances in Neural Information Processing Systems 32.
Song, Yang, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2021. “Score-Based Generative Modeling Through Stochastic Differential Equations.” In International Conference on Learning Representations.
Vincent, Pascal. 2011. “A Connection Between Score Matching and Denoising Autoencoders.”Neural Computation 23 (7): 1661–74.